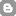Il y a quelques semaines, j'ai présenté un exemple d'utilisation de la librairie Geotools pour la manipulation de données géographiques.
Après avoir éprouvé ce code face à des volumétries importantes, j'ai pu constater quelques problèmes de montées en charge de la JVM, tels qu'illustrés ici :

Face à un jeu de test d'environ 200Mo de fichiers Shapefile (représentant approximativement 700.000 lignes en base), on voit clairement les pics de charge dus à l'ajout en mémoire du contenu total des fichiers avant injection en base de données.
Je vais donc ici présenter une façon d'améliorer le code décrit précédemment afin de mieux gérer la mémoire utilisée.
Geotools fournit deux objets très utiles pour gérer les données utilisées sous la forme de flux :
- Dans le cas de l'injection en base de données provenant de Shapefiles :
FeatureReader<SimpleFeatureType, SimpleFeature>qui permet de lire en continu les features présentes dans un fichier - Dans le cas de l'extraction des données d'une base vers un fichier Shapefile :
Query.setMaxFeatures(int)etQuery.setStartIndex(int)permettent la pagination des requêtes SQL.
Voici donc comment les utiliser :
private static final int MAX_MEMORY_FEATURES = 15000;
private static final String POSTGIS_TABLENAME = "MY_TABLE";
private static GeoProperties props = GeoProperties.getInstance();
private static CamelProperties camelprops = CamelProperties.getInstance();
private static ShapefileDataStoreFactory shpFactory = new ShapefileDataStoreFactory();
private static FeatureTypeFactoryImpl factory = new FeatureTypeFactoryImpl();
private static DataStore pgStore;
private SimpleFeatureType schema;
private static Log LOGGER = LogFactory.getLog("camel");
public GeoToPostGISClient() throws Exception {
try {
Logging.GEOTOOLS.setLoggerFactory("org.geotools.util.logging.Log4JLoggerFactory");
} catch (Exception e) {
LOGGER.warn("Log factory not found for GeoTools : 'org.geotools.util.logging.Log4JLoggerFactory'");
}
// Ouvrir une connexion vers la base PostGIS
getDataStore();
}
private void getDataStore() throws Exception {
if (pgStore == null) {
PostgisDataStoreFactory pgFactory = new PostgisDataStoreFactory();
Map<String, String> jdbcparams = new HashMap<String, String>();
jdbcparams.put(PostgisDataStoreFactory.DBTYPE.key, "postgis");
jdbcparams.put(PostgisDataStoreFactory.HOST.key, props.getProperty(GeoProperties.DB_HOST));
jdbcparams.put(PostgisDataStoreFactory.PORT.key, props.getProperty(GeoProperties.DB_PORT));
jdbcparams.put(PostgisDataStoreFactory.SCHEMA.key, props.getProperty(GeoProperties.DB_SCHEMA));
jdbcparams.put(PostgisDataStoreFactory.DATABASE.key, props.getProperty(GeoProperties.DB_NAME));
jdbcparams.put(PostgisDataStoreFactory.USER.key, props.getProperty(GeoProperties.DB_USER));
jdbcparams.put(PostgisDataStoreFactory.PASSWD.key, props.getProperty(GeoProperties.DB_PWD));
pgStore = pgFactory.createDataStore(jdbcparams);
}
}
/**
* Insert all specified shapefiles in Postgre
*
* @param shapefilePaths files
* @throws IOException all
*/
public void insertShpIntoDb(List<String> shapefilePaths) throws Exception {
Iterator<String> iterator = shapefilePaths.iterator();
String path = null;
while (iterator.hasNext()) {
path = iterator.next();
LOGGER.info("Inserting : " + path);
Map<String, Object> shpparams = new HashMap<String, Object>();
shpparams.put("url", "file://" + path);
FileDataStore shpStore = (FileDataStore) shpFactory.createDataStore(shpparams);
if (schema == null) {
LOGGER.info("Create schema");
// Copy schema and change name in order to refer to the same
// global schema for all files
SimpleFeatureType originalSchema = shpStore.getSchema();
Name originalName = originalSchema.getName();
NameImpl theName = new NameImpl(originalName.getNamespaceURI(), originalName.getSeparator(), POSTGIS_TABLENAME);
schema = factory.createSimpleFeatureType(theName, originalSchema.getAttributeDescriptors(), originalSchema.getGeometryDescriptor(),
originalSchema.isAbstract(), originalSchema.getRestrictions(), originalSchema.getSuper(), originalSchema.getDescription());
pgStore.createSchema(schema);
}
// Ajout des objets du shapefile dans la table PostGIS
// Query.FIDS : To request only the feature IDs with no content
int totalSHPentries = shpStore.getFeatureSource().getCount(Query.FIDS);
int insertedEntries = 0;
SimpleFeatureStore featureStore = (SimpleFeatureStore) pgStore.getFeatureSource(POSTGIS_TABLENAME);
DefaultTransaction transaction = null;
FeatureReader<SimpleFeatureType, SimpleFeature> featureReader = shpStore.getFeatureReader();
SimpleFeatureCollection features = new DefaultFeatureCollection(null, featureReader.getFeatureType());
while (featureReader.hasNext()) {
features.add(featureReader.next());
if (features.size() == MAX_MEMORY_FEATURES || !featureReader.hasNext()) {
transaction = new DefaultTransaction("bulk");
featureStore.setTransaction(transaction);
try {
LOGGER.info("Inserting features " + insertedEntries + " to " + (insertedEntries + features.size()) + " from "
+ totalSHPentries);
featureStore.addFeatures(features);
transaction.commit();
insertedEntries += features.size();
features = new DefaultFeatureCollection(null, featureReader.getFeatureType());
// To avoid memory leaks
System.gc();
} catch (Exception problem) {
LOGGER.error(problem.getMessage(), problem);
transaction.rollback();
break;
} finally {
transaction.close();
}
}
}
featureReader.close();
features = null;
// To avoid memory leaks
System.gc();
shpStore.dispose();
LOGGER.info("End insert");
}
extractFromDb();
}
/**
* Extracts local data from postgis DB
*
* @throws IOException all
*/
public void extractFromDb() throws IOException {
// Faire une requête spatiale dans la base
SimpleFeatureCollection filteredFeatures = null;
String destFolder = camelprops.getProperty(CamelProperties.CAMEL_WORK_DIR) + "/shp/";
LOGGER.info("Extracting data");
for (Object dep : ReferentielDepartement.getDepartements()) {
try {
// Check data presence in DB
Filter deptFilter = CQL.toFilter("DPT_NUM = '" + dep + "'");
Query qCount = new Query(pgStore.getTypeNames()[0], deptFilter);
int count = pgStore.getFeatureSource(POSTGIS_TABLENAME).getCount(qCount);
if (count > 0) {
// Écrire le résultat dans un fichier shapefile
Map<String, String> destshpparams = new HashMap<String, String>();
String destinationSchemaName = ShapeFileNamesRules.computeNameFor((String) dep);
destshpparams.put("url", "file://" + destFolder + destinationSchemaName + ".shp");
DataStore destShpStore = shpFactory.createNewDataStore(destshpparams);
// duplicate existing schema to create destination's one
Name originalName = schema.getName();
NameImpl theName = new NameImpl(originalName.getNamespaceURI(), originalName.getSeparator(), destinationSchemaName);
SimpleFeatureType destschema = factory
.createSimpleFeatureType(theName, schema.getAttributeDescriptors(), schema.getGeometryDescriptor(), schema.isAbstract(),
schema.getRestrictions(), schema.getSuper(), schema.getDescription());
destShpStore.createSchema(destschema);
// destination store
SimpleFeatureStore destFeatureStore = (SimpleFeatureStore) destShpStore.getFeatureSource(destinationSchemaName);
// Query DB
int extractedData = 0;
Query q = null;
while (extractedData < count) {
q = new DefaultQuery(pgStore.getTypeNames()[0], deptFilter, MAX_MEMORY_FEATURES, null, "extractQuery");
q.setStartIndex(extractedData);
filteredFeatures = pgStore.getFeatureSource(POSTGIS_TABLENAME).getFeatures(q);
if (filteredFeatures != null && filteredFeatures.size() > 0) {
LOGGER.info("Extracting features " + extractedData + " to " + filteredFeatures.size() + " from " + count + " for " + dep);
destFeatureStore.addFeatures(filteredFeatures);
}
extractedData += MAX_MEMORY_FEATURES;
}
// Fermer les connections et les fichiers
LOGGER.info("End extract");
destShpStore.dispose();
}
} catch (CQLException e) {
LOGGER.error(e.getMessage(), e);
}
}
// Write done file for Camel
File done = new File(destFolder + "done");
done.createNewFile();
done = null;
}
Avec ce code, les données sont insérées en base ou extraites par lot de 15000, ce qui permet de limiter la surcharge de la JVM. Voici le résultat :

On voit distinctement les montées en charge pour chaque fichier traité, mais le tout est lissé et limité autour de 30Mo, ce qui permet de plus facilement calibrer l'environnement final de l'application. Un exemple de log produit :
780617 INFO camel - Inserting : C:\test\shp\RPG_2010_064.shp 781164 INFO camel - Inserting features 0 to 15000 from 120834 813128 INFO camel - Inserting features 15000 to 30000 from 120834 845466 INFO camel - Inserting features 30000 to 45000 from 120834 875914 INFO camel - Inserting features 45000 to 60000 from 120834 907550 INFO camel - Inserting features 60000 to 75000 from 120834 937530 INFO camel - Inserting features 75000 to 90000 from 120834 968837 INFO camel - Inserting features 90000 to 105000 from 120834 998942 INFO camel - Inserting features 105000 to 120000 from 120834 1028405 INFO camel - Inserting features 120000 to 120834 from 120834 1030327 INFO camel - End insert 1030327 INFO camel - Inserting : C:\test\shp\RPG_2010_080.shp 1030733 INFO camel - Inserting features 0 to 15000 from 86010 1056963 INFO camel - Inserting features 15000 to 30000 from 86010 1084584 INFO camel - Inserting features 30000 to 45000 from 86010 1111438 INFO camel - Inserting features 45000 to 60000 from 86010 1136965 INFO camel - Inserting features 60000 to 75000 from 86010 1161602 INFO camel - Inserting features 75000 to 86010 from 86010 1180505 INFO camel - End insert