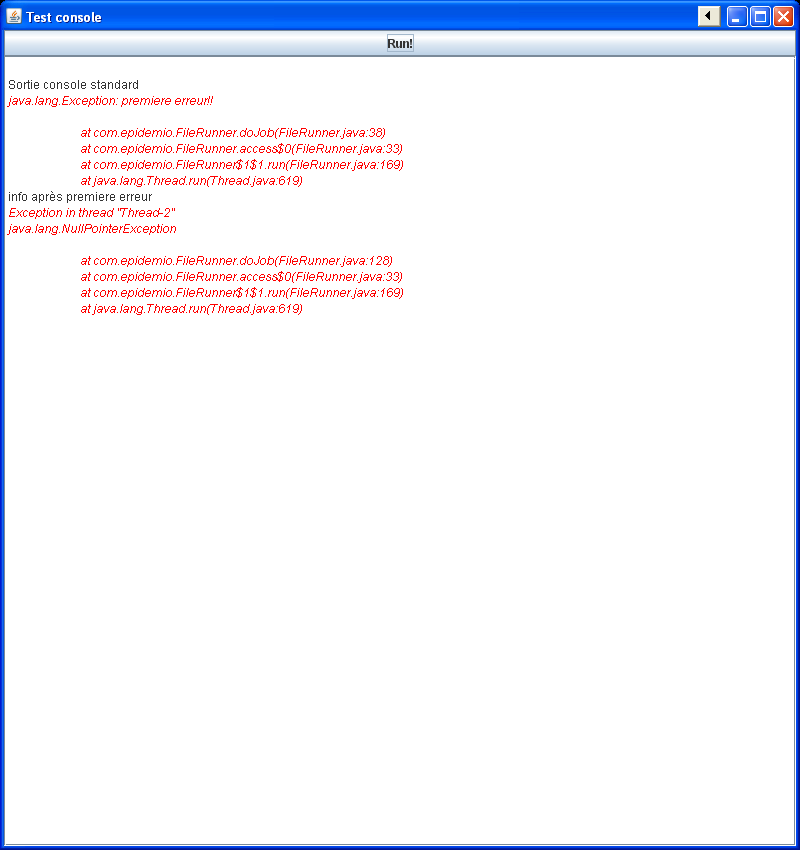
Voici la problématique à résoudre : un outil a été développé en prévision de n'être exécuté qu'en ligne de commande. Toutes les informations ressorties le sont donc via System.out ou System.err. Or il se trouve maintenant qu'il est nécessaire d'intégrer cet outil dans une application comportant une interface graphique et donc de diriger les sorties vers un composant graphique en y ajoutant un formatage selon le type de message. Il est bien sûr impossible de modifier le code de l'outil... Voici un aperçu du résultat attendu :
Pour résoudre ceci, il faut commencer par redéfinir la sortie des messages. Java offre cette possibilité à l'aide de :
System.setOut(...);
System.setErr(...);
Ces deux méthodes attendent en entrée un objet héritant de java.io.PrintStream. Mais avant de voir comment mettre en place ces éléments, regardons comment est créée l'interface :
public static void buildGUI() throws Exception {
final CustomConsole out = new CustomConsole();
JScrollPane sp = new JScrollPane(out.getOutComponent());
JButton btn = new JButton("Run!");
btn.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
out.clear();
Thread t = new Thread(new Runnable() {
@Override
public void run() {
doJob();
}
});
t.start();
}
});
JPanel p = new JPanel(new BorderLayout());
p.add(btn, BorderLayout.NORTH);
p.add(sp, BorderLayout.CENTER);
JFrame f = new JFrame("Test console");
f.setSize(800, 850);
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.add(p);
f.setVisible(true);
}
Cette première méthode utilise des objets Swing courants pour construire l'interface, et introduit CustomConsole : c'est dans cette classe que réside toute notre customisation. Voici son contenu :
public class CustomConsole {
private JTextPane outComponent;
public CustomConsole() throws Exception {
this.outComponent = new JTextPane() {
private static final long serialVersionUID = 8575888440178628669L;
// to remove line wrap
public boolean getScrollableTracksViewportWidth() {
return getUI().getPreferredSize(this).width <= getParent().getSize().width;
}
@Override
public void setEditable(boolean b) {
super.setEditable(false);
}
};
// build error style
Style def = StyleContext.getDefaultStyleContext().getStyle(StyleContext.DEFAULT_STYLE);
Style s = outComponent.getStyledDocument().addStyle("error", def);
StyleConstants.setForeground(s, Color.RED);
StyleConstants.setItalic(s, true);
// define standard out
System.setOut(new CustomOutStream(outComponent));
System.setErr(new CustomErrStream(outComponent));
}
public JTextPane getOutComponent() {
return outComponent;
}
public void clear() {
outComponent.setText("");
}
}
Comme vous pouvez le constater, le code est assez simple. La définition du style de police pour les messages d'erreurs se fait à partir du style standard de police du JTextPane auquel on ajoute nos caractéristiques. Notez la subtilité lors de la définition de cet objet : pour empêcher les retours à la ligne lors de l'affichage, on surcharge la méthode getScrollableTracksViewportWidth(). Enfin, la suite de notre personnalisation réside dans les objets CustomOutStream et CustomErrStream : mais là encore, rien de très compliqué, les deux classes sont quasiment identiques :
public class CustomOutStream extends CustomPrintStream {
private JTextPane outComponent;
public CustomOutStream(JTextPane area) throws Exception {
super();
outComponent = area;
}
@Override
public void write(byte buf[], int off, int len) {
addToConsole(new String(buf, off, len));
}
@Override
public void write(int b) {
addToConsole(new String(new char[] { (char) b }));
}
@Override
public void println(String x) {
addToConsole(x);
}
private void addToConsole(String s) {
StyledDocument doc = outComponent.getStyledDocument();
try {
if (!s.endsWith("\n")) {
println();
}
doc.insertString(doc.getLength(), s, doc.getStyle(StyleContext.DEFAULT_STYLE));
} catch (BadLocationException e) {
e.printStackTrace();
}
outComponent.setCaretPosition(doc.getLength() - s.length());
}
}
Elles redéfinissent les méthodes d'écriture les plus courantes afin de nous permettre de gérer les styles : dans cet exemple, pour la sortie standard, on choisi d'utiliser la police par défaut, correspondant au style StyleContext.DEFAULT_STYLE.
Pour ce qui est de la sortie d'erreur, on utilise le même code en remplaçant simplement le style par celui défini dans la console (italique rouge) : doc.getStyle("error")
L'instruction setCaretPosition permet de créer l'effet d'autoscroll sur la console.
Pour unifier la création du flux de sortie, j'ai créé la classe ci-dessous, mère des classes précédentes :
public class CustomPrintStream extends PrintStream {
public CustomPrintStream() throws FileNotFoundException, UnsupportedEncodingException {
// on indique un fichier texte parce que requis mais non utilisé ici
// et on indique l'encodage désiré pour cette console
super(new FileOutputStream("C:\\empty.txt"), true, "ISO-8859-1");
}
}
Cette console peut alors être testée avec ce simple code :
private static void doJob() {
FileInputStream fstream = null;
try {
System.out.println("Sortie console standard");
if(true) {
throw new Exception("premiere erreur!!");
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("info après premiere erreur");
} finally {
try {
fstream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Nous avons donc pu créer cette interface graphique sans modifier le code de l'outil de base.
Hope this helps!
Sources :
Fichier(s) joint(s) :